python真题
计算机二级python真题相信大家都是比较熟悉的,这一课程就是分析python真题第一套第一小题,首先需要对这道题进行分析,分析完成以后点击考试文件夹打开我们所需要的文件,下一步就是精修代码的联系书写,在进行书写的时候要注意规范的问题,并且在书写完成以后要注意检查运行的结果是否正确,下面让我们来详细的了解一下关于python真题的知识介绍吧!
计算机二级python真题:第1套第1小题
1、本节课结合题目和笔记,进行操作,首先分析【第41小题】。
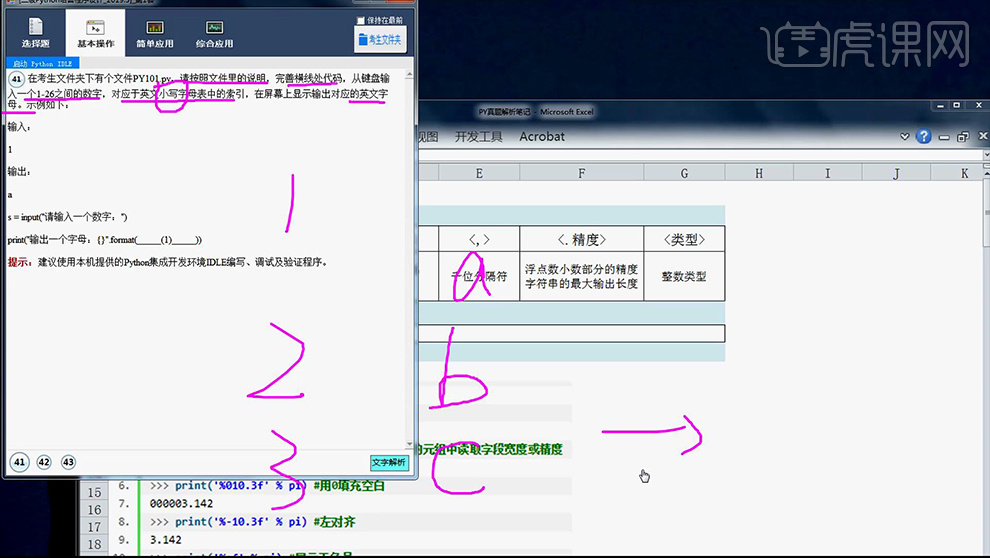
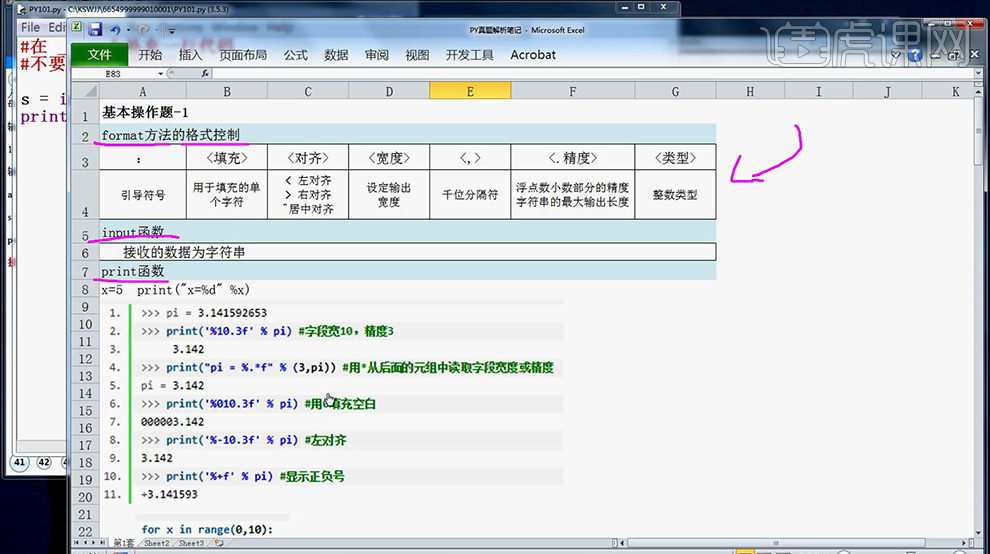
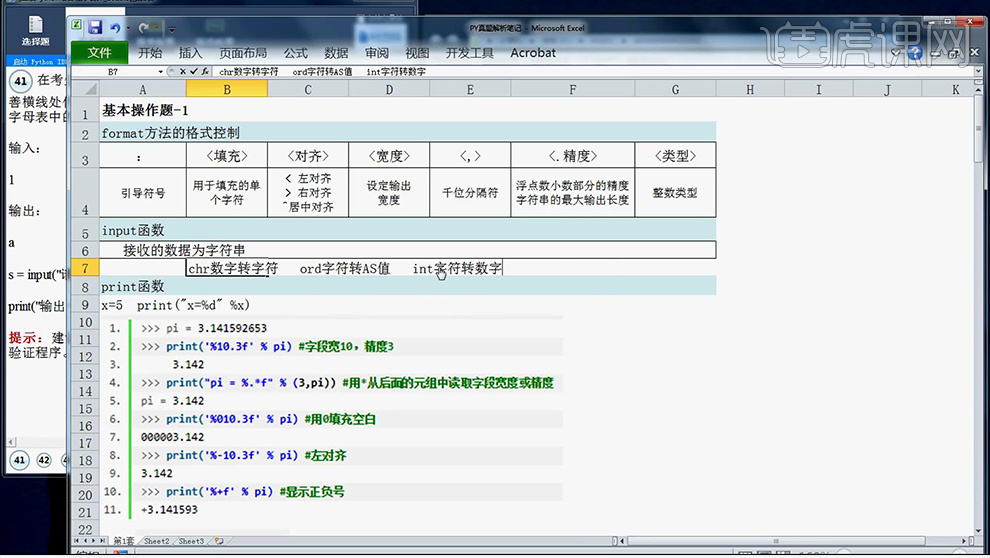
2、分析完成后,点击【考试文件夹-点击Py101】【本小题需要掌握的考点:format方法的格式控制、input函数。print函数】笔记内容如图。
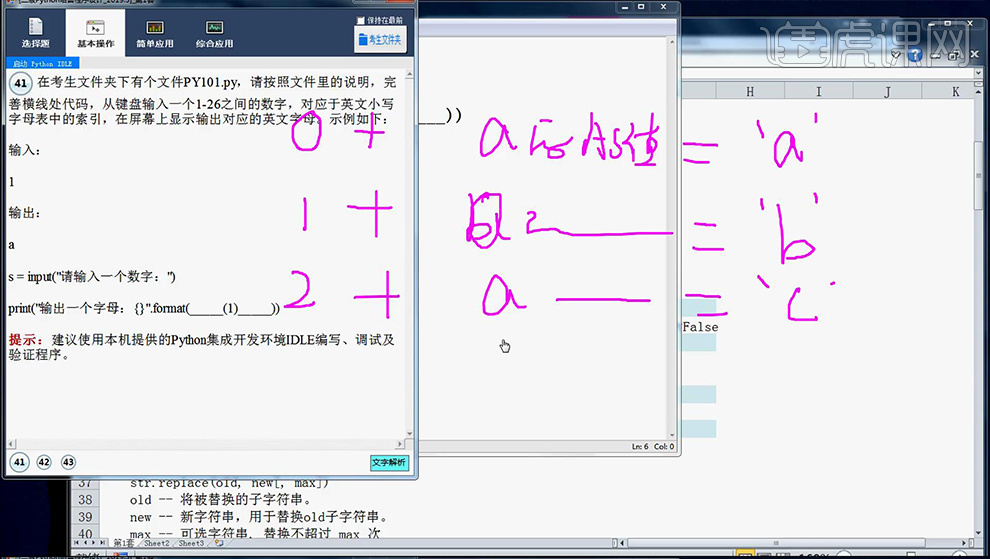
3、然后讲解【该小题的算法】算法如草图。
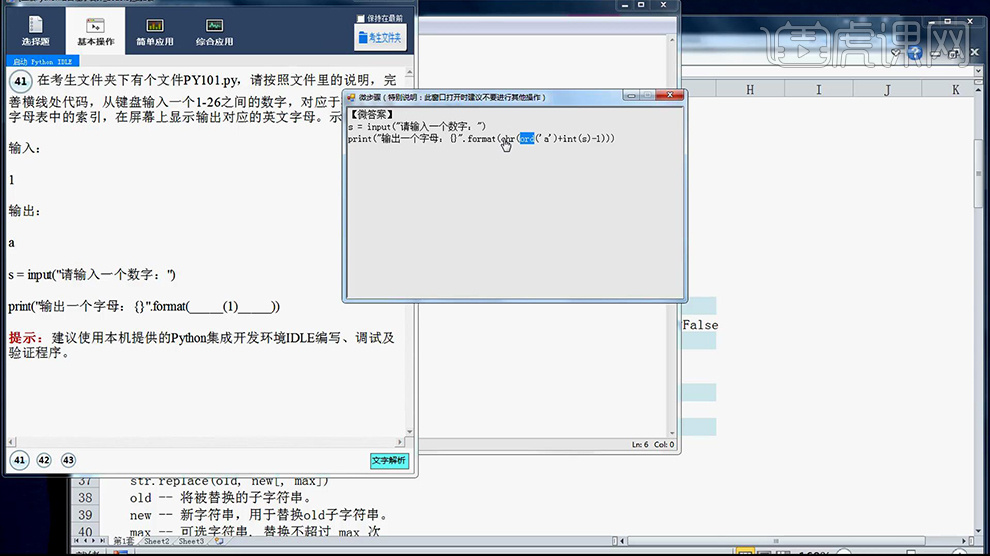
4、然后点击【有下角的文字解析】答案如图。
5、然后进行【代码的练习书写】(笔记中的函数要认真观看,可以截图保存之后熟记)代码如图所示。
6、然后回到【考试文件夹中】进行【代码的书写】代码如图。

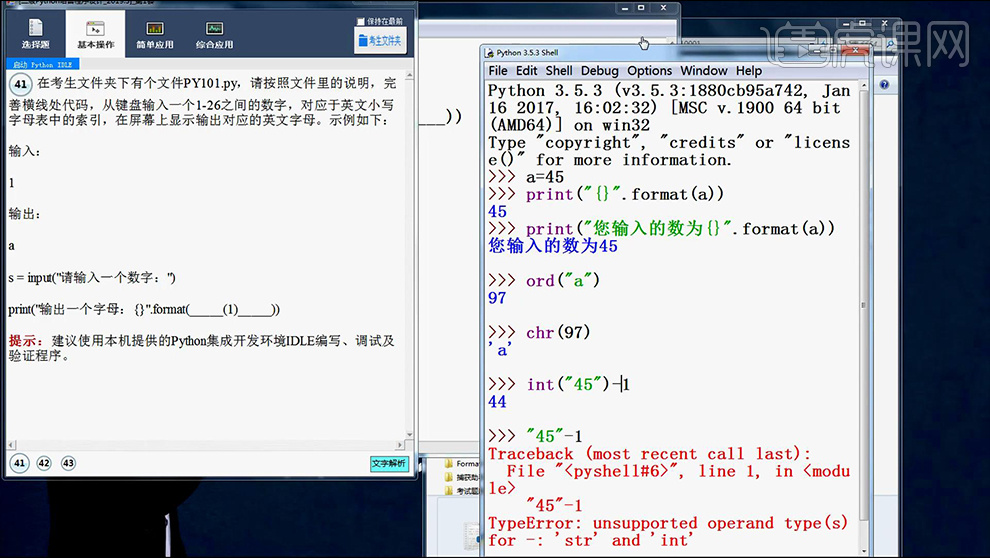
7、书写完成后,按【F5键运行-任意输入数字】查看运行结果是否正确。

8、本节课所用到的【三个函数如图】。
9、本节课内容到此结束。

计算机二级python真题:第1套第2小题
1、首先分析本节课的课程题目。
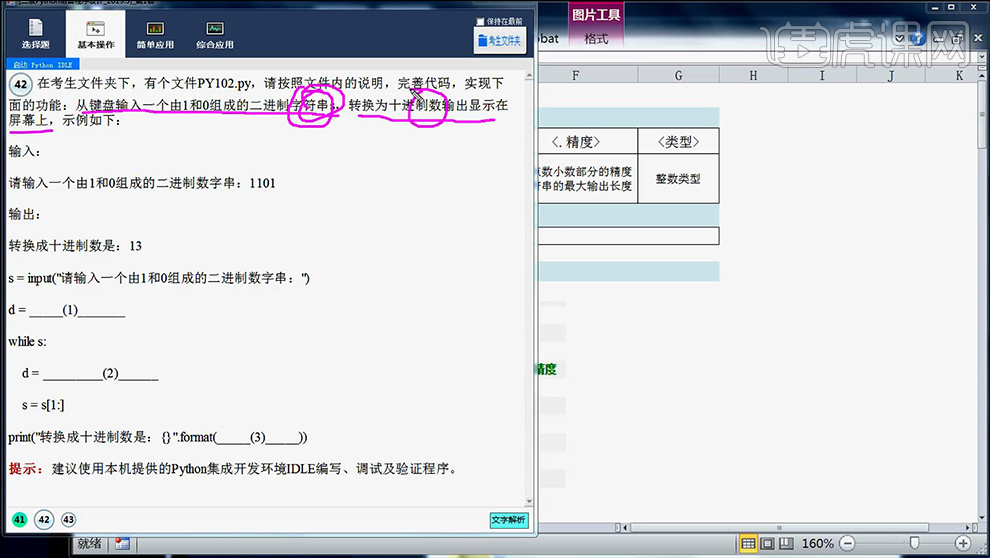
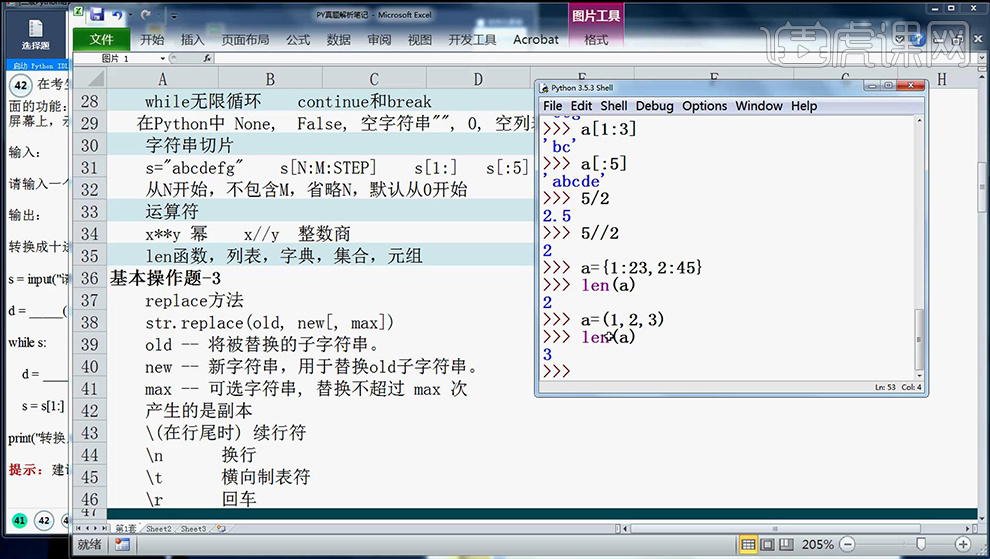
2、在【Python中指数运算用**n表示】【获取字符串的方法字符串切片】笔记如图所示。
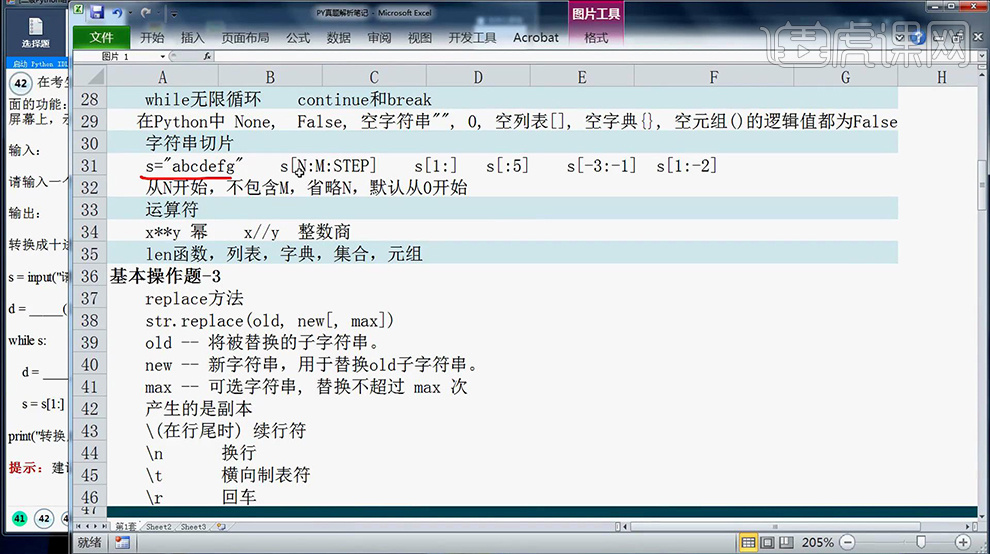
3、【s[1:]表示从1开始之后的全部取完;s[:从0开始到第4为];s[-3:-1]表示从倒数第三个到倒数第一个;s[1:-2]是从第一个到倒数第二个】。
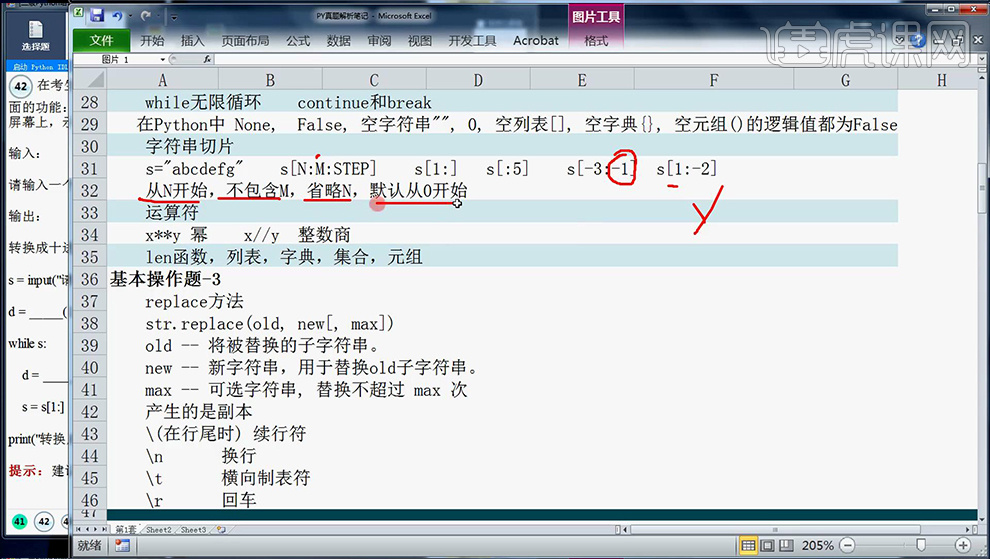
4、分析完笔记后,然后在【Python中进行联系书写】。
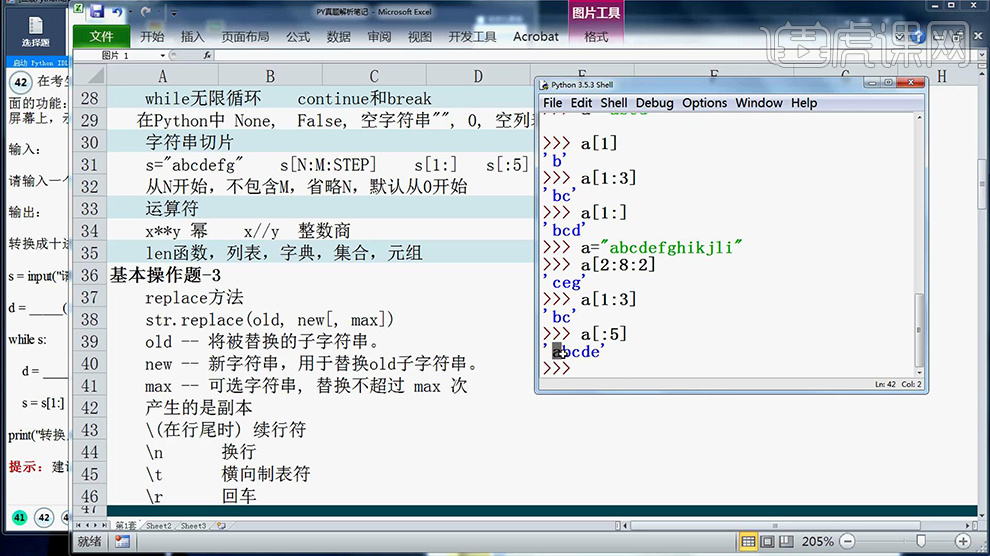
5、【1101需要进行4次切片】可以联系到【循环for/while】。
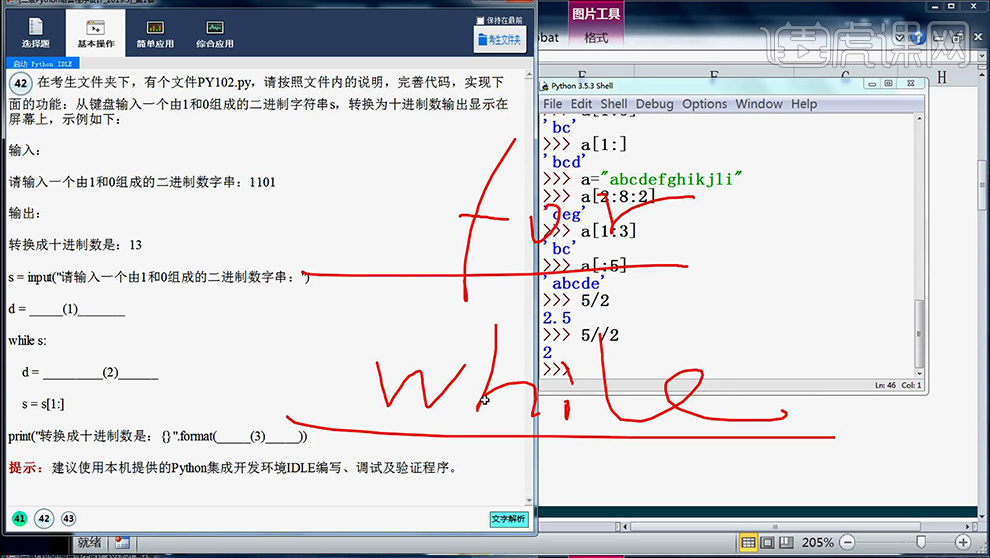
6、然后点击右下角【文字解析】查看本题的答案。
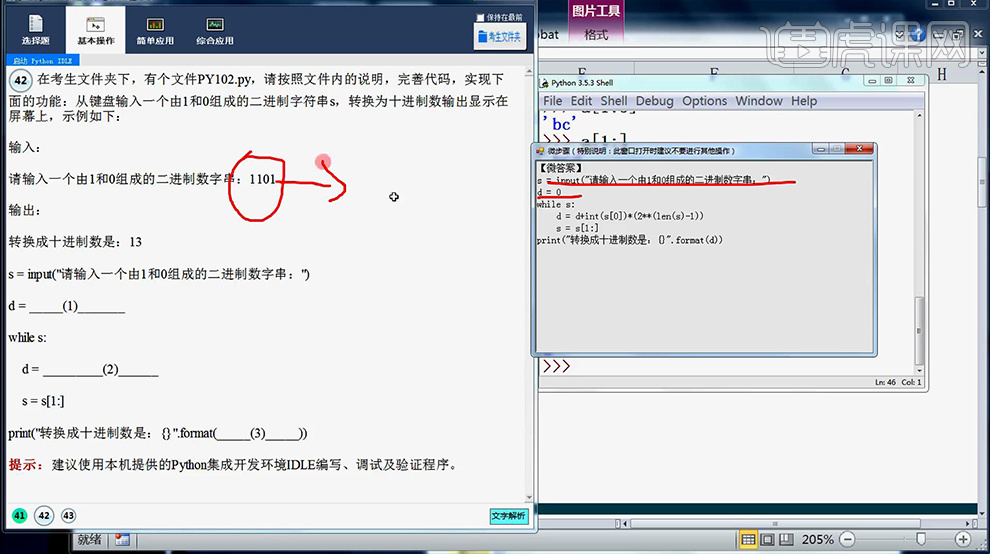
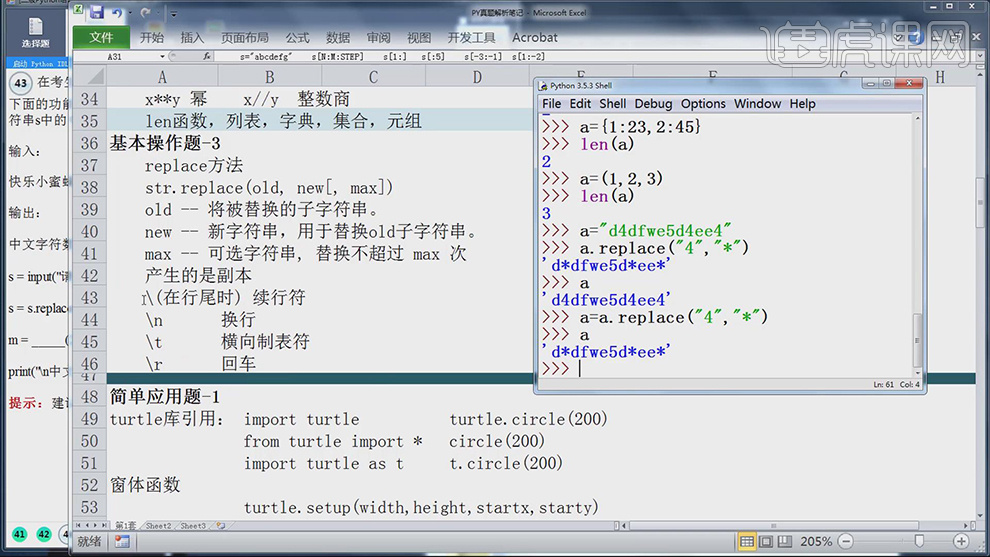
7、然后对【len函数进行分析】(边操作边分析)。
8、对答案分析完成后进行实例的操作演示,演示之前对【while循环】复习一下。
9、【实例演示】打开【考试文件夹】然后代码的填写,【代码如图所示】。
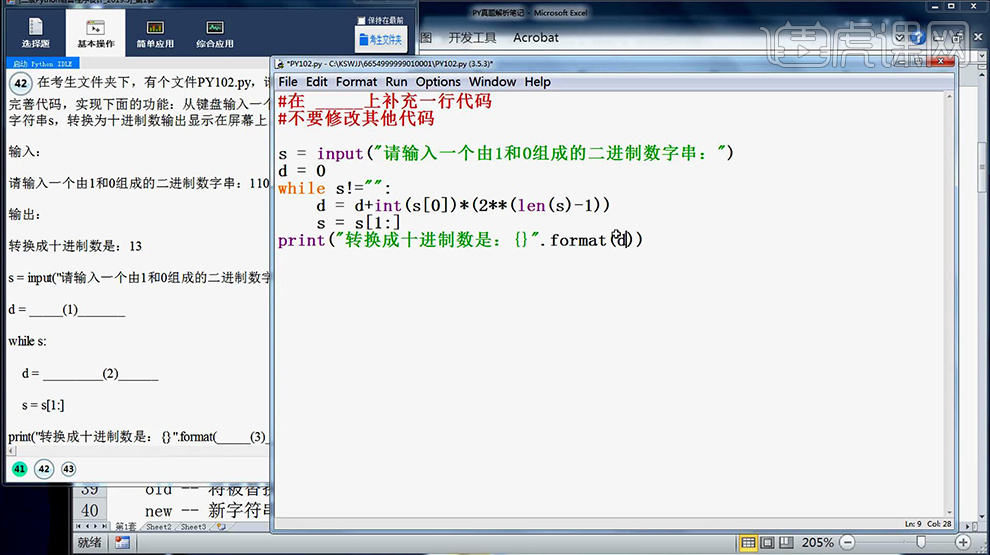
10、填写完成后按【F5运行】查看是否成功。
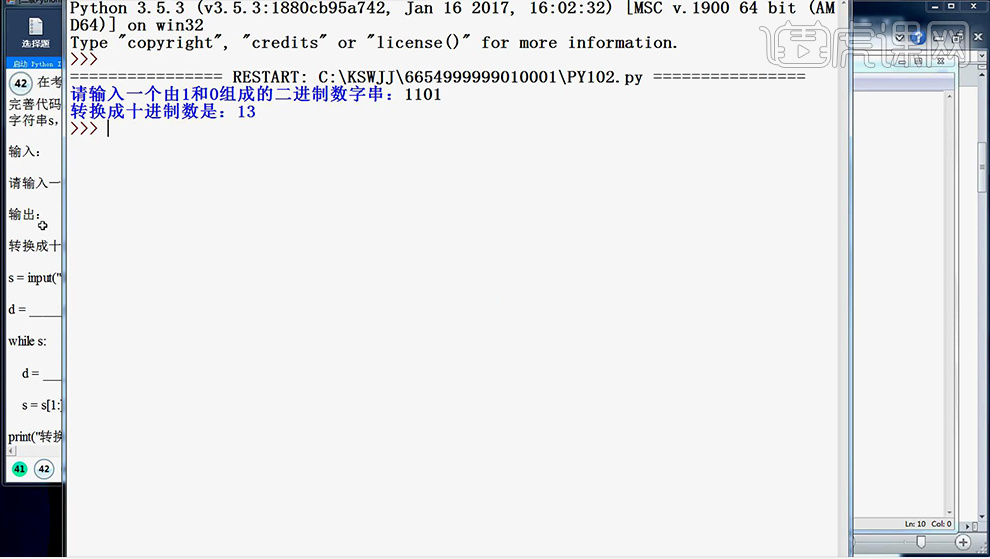
11、本节课内容到此结束。

计算机二级python真题:第1套第3小题
1.replace方法是替换方法,将后方字符串替换前方字符串,max为替换次数,会产生副本,不会去修改原字符串。\n为换行,\t为横向制表符,\r为回车。
2.结题思路为第一步将逗号与句号从字符串中去掉,第二步利用len函数把长度测试个数得到结果。
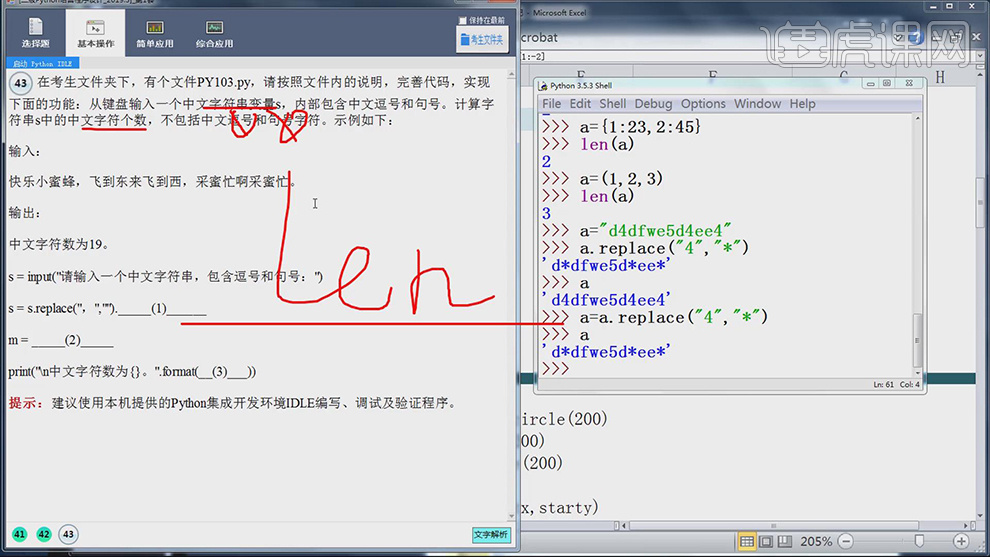
3.【打开】考生文件夹,选择【PY103.py】,【右键】-【Edit With IDLE】-【Edit with IDLE 3.5(64-bit)】,进入【程序】文件,具体如图示。
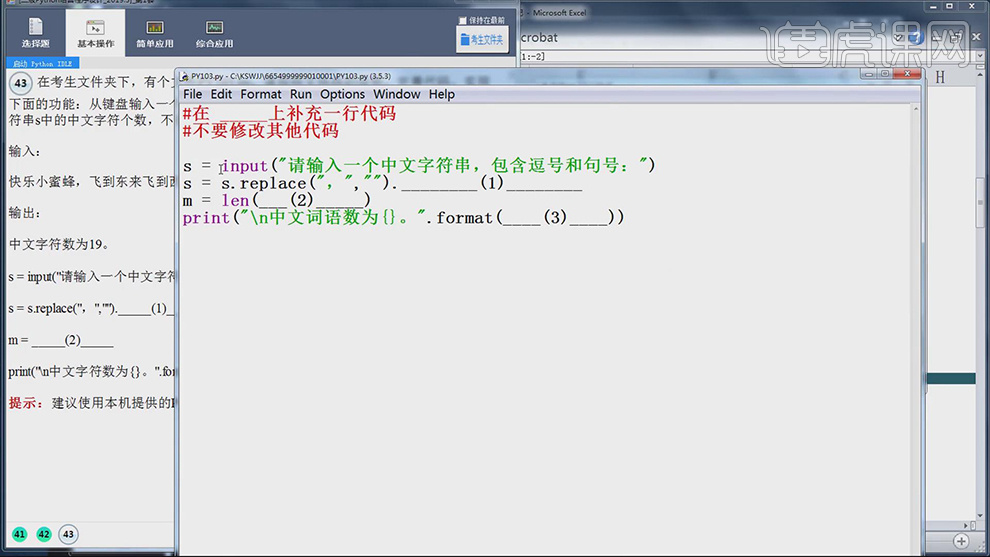
4.输入【s=s.replace(“。”“,”)】,输出【空字符串】可替换句号和逗号,具体如图示。
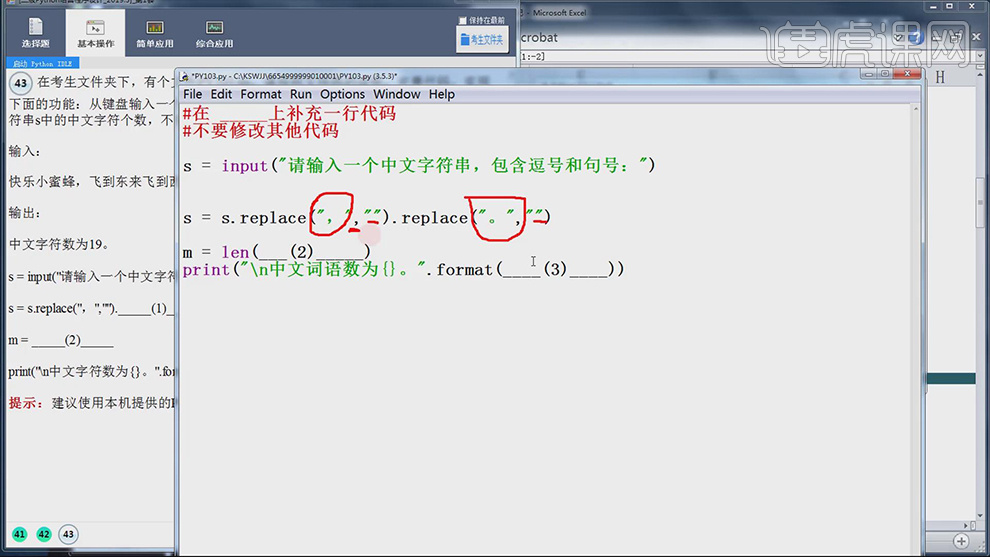
5.输入【代码】m=len(s),测出s的长度,最后输出【s】,具体如图示。
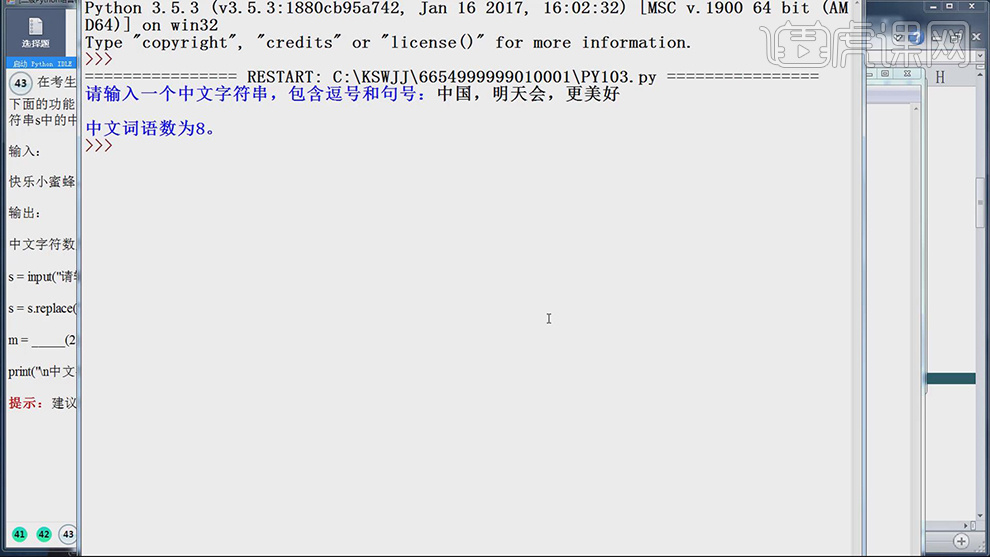
6.按【F5】运行,输入【字符串】,按【回车键】得到答案,具体如图示。
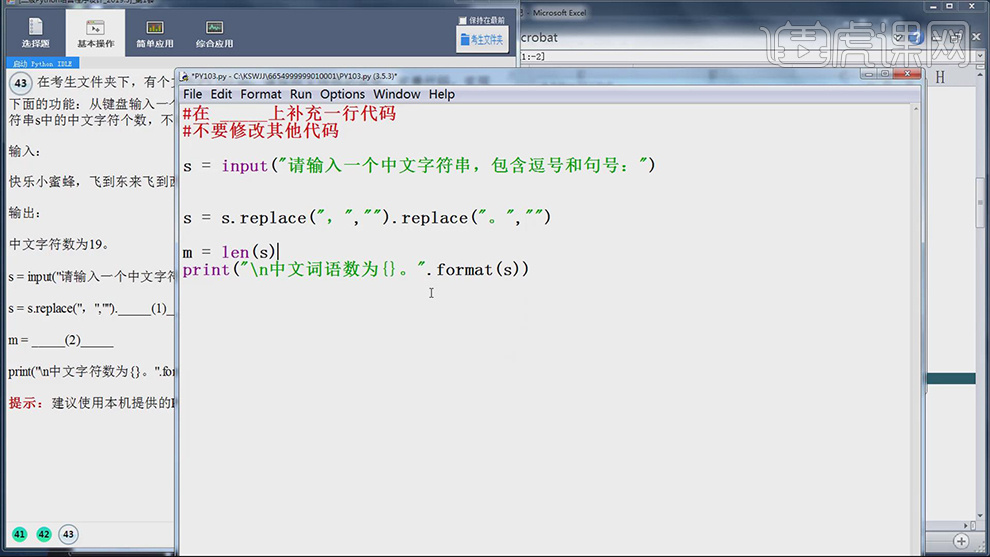
7.回到【代码原文件】,修复代码为m=len(s),测出m的长度,最后输出【m】,具体如图示。
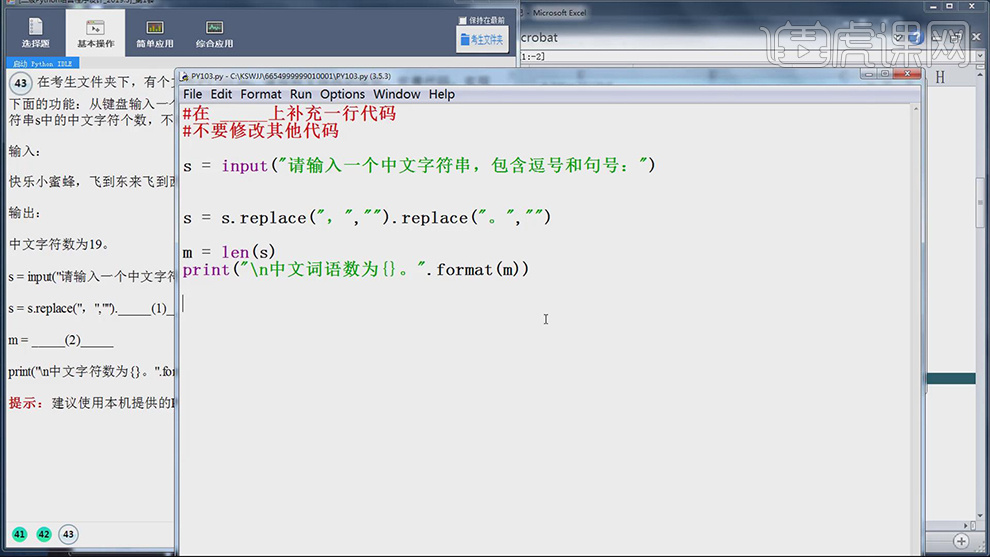
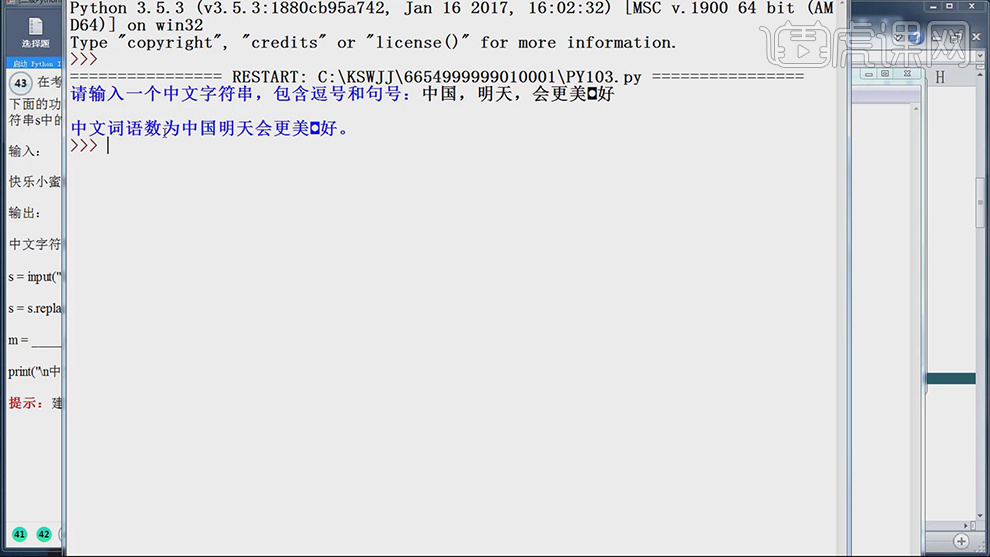
8.按【F5】运行,输入【字符串】,按【回车键】得到答案,具体如图示。
计算机二级python真题:第1套第4小题
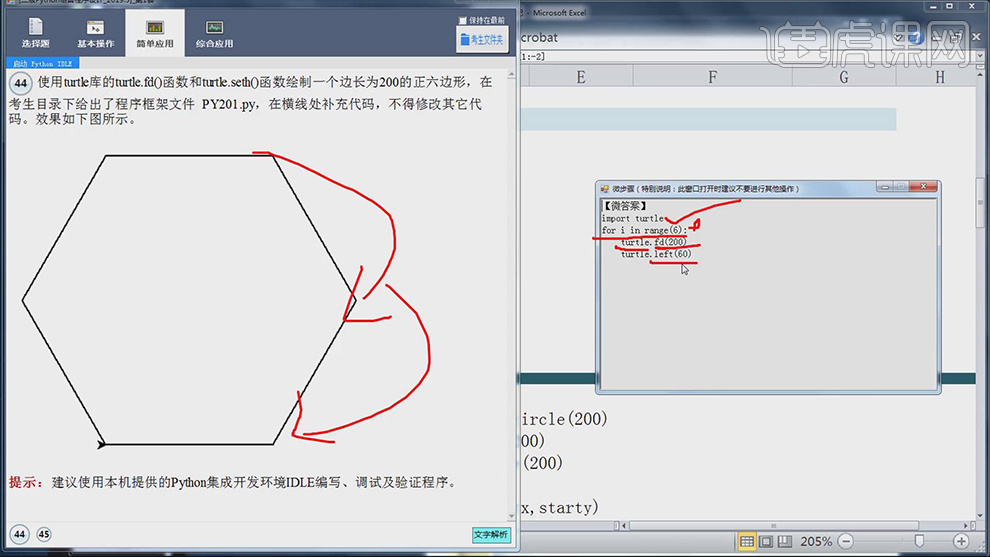
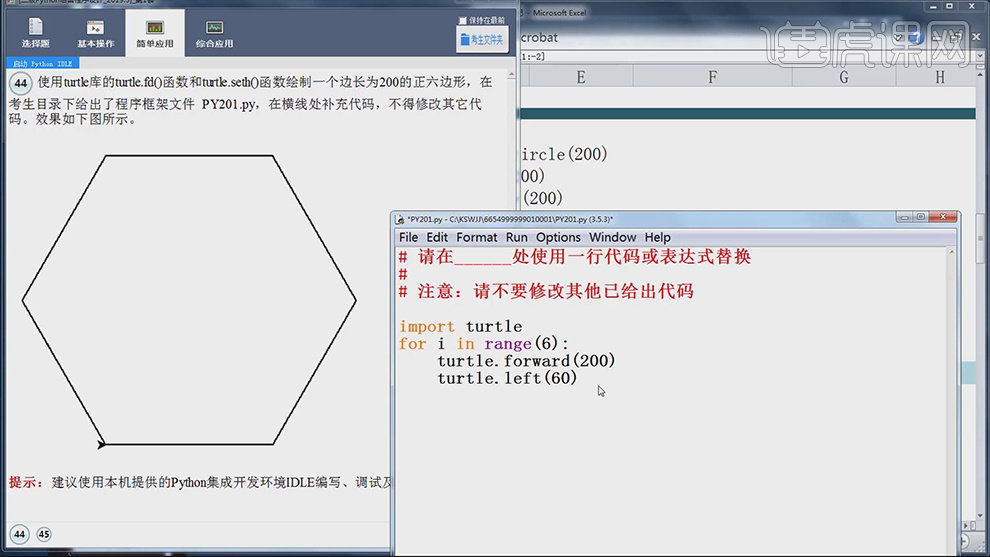
1.角的度数都是60,点击【文字解析】,import turtle引用turtle第三方函数库,再利用for语句循环,turtle.fd(200)前进200,turtle.left(60)旋转左60。
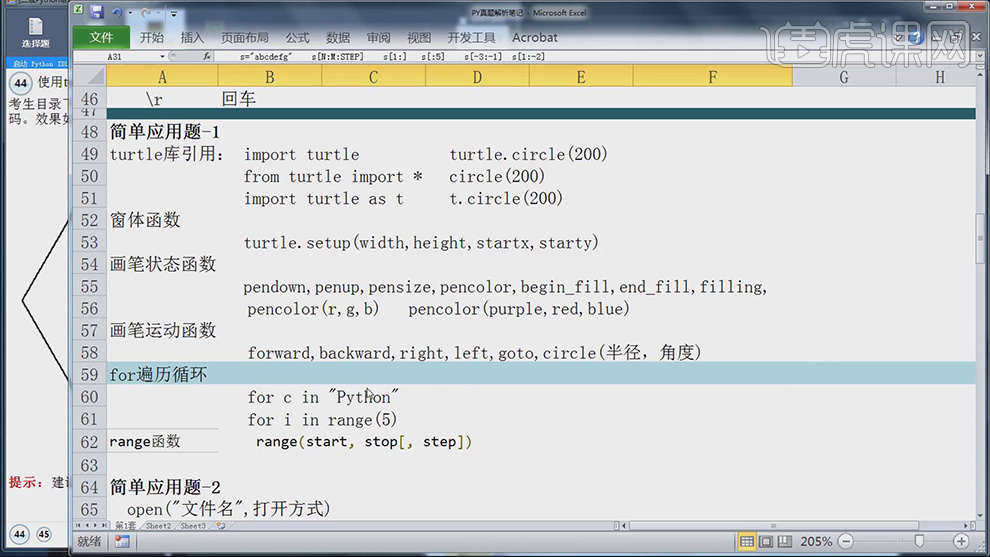
2.第三方turtle库的引用有三种方法:import turtle、from turtle import *、import turtle as t。以及窗体函数、画笔状态函数、画笔运动函数、for遍历循环具体如图示。
3.点击【考生文件夹】,选择【PY201】,【右键】-【Edit with IDLE】-【Edit with IDLE 3.5】,输入【代码】,具体如图示。
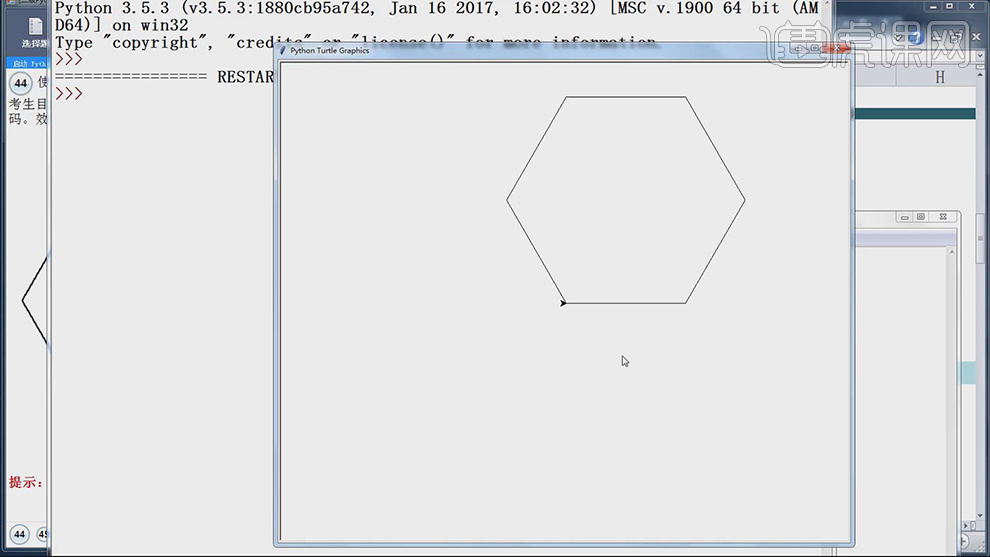
4.按【F5】运行,得到结果如图示。
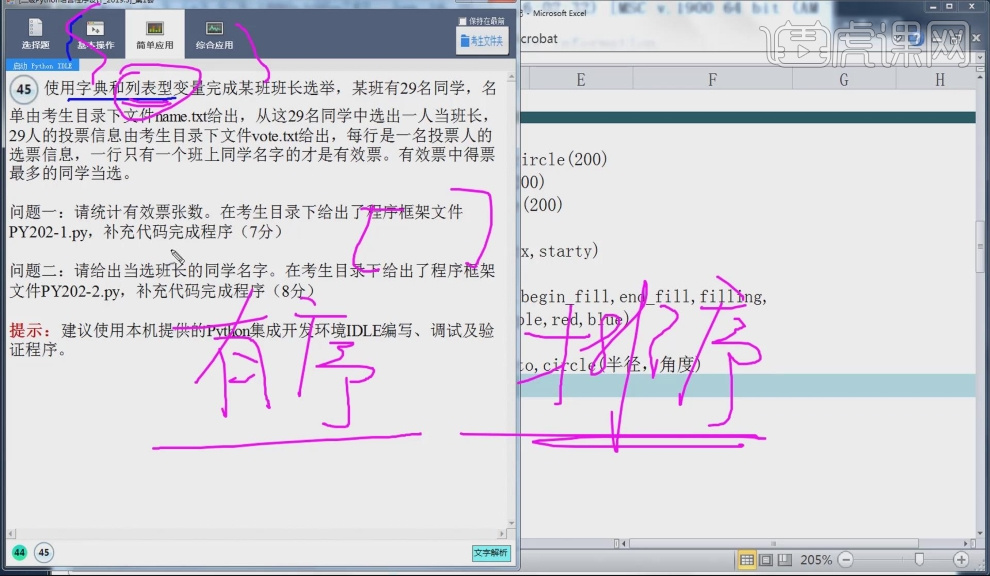
计算机二级python真题:第1套第5小题
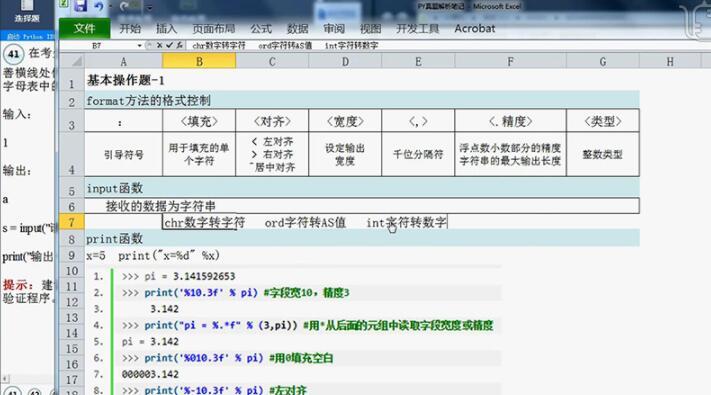
1.字典型数据格式要求“{}”结合“:”,列表型数据格式要求“[]”,只有列表型是有序的。
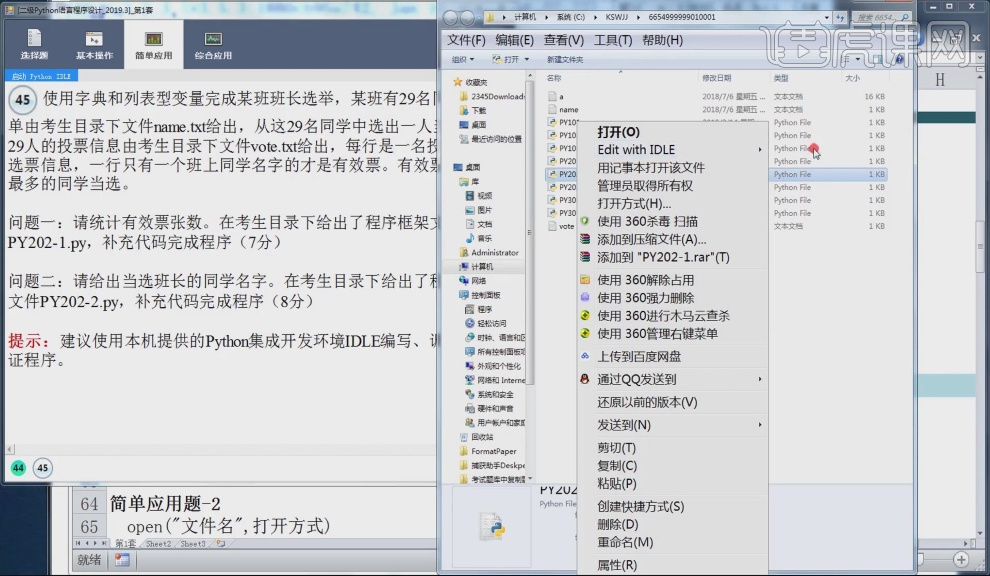
2.单击【考生文件夹】,打开程序文件【py202-1】。
3.【open】函数格式:open("文件名",打开方式),其中文件名要加双引号,当省略打开方式时,会以默认模式r打开。
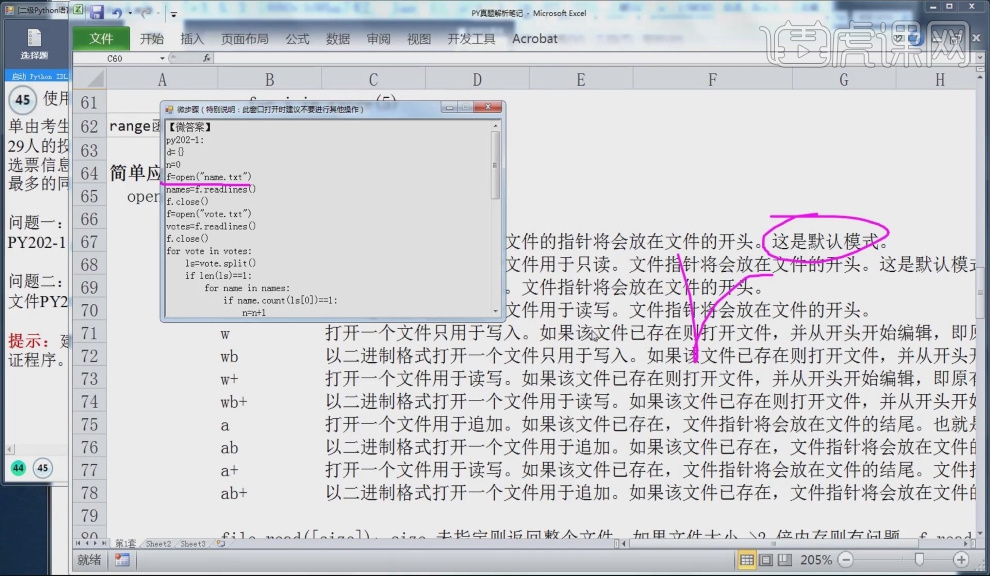
4.模式r与模式rb都是以只读方式打开文件,但模式rb以二进制格式打开文件。
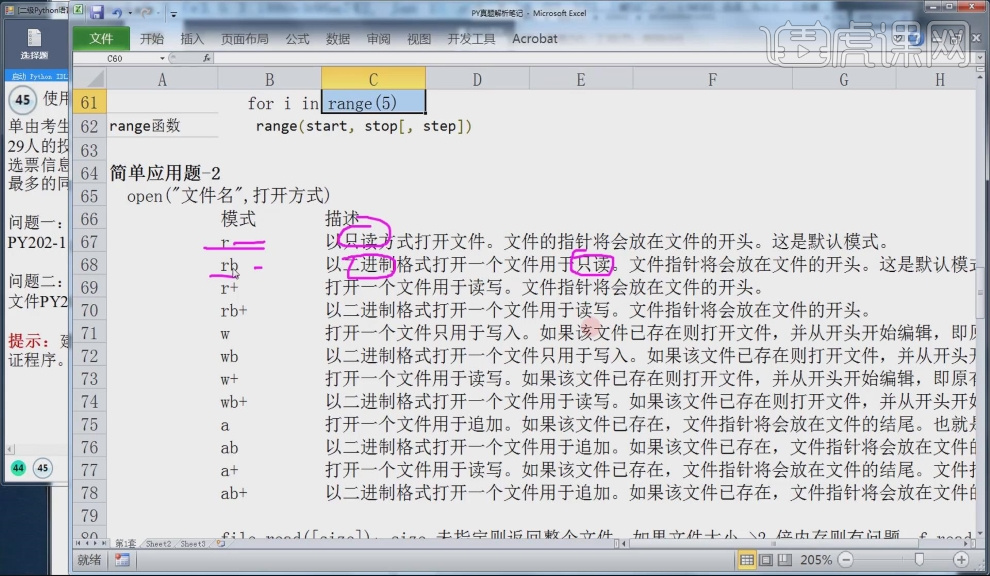
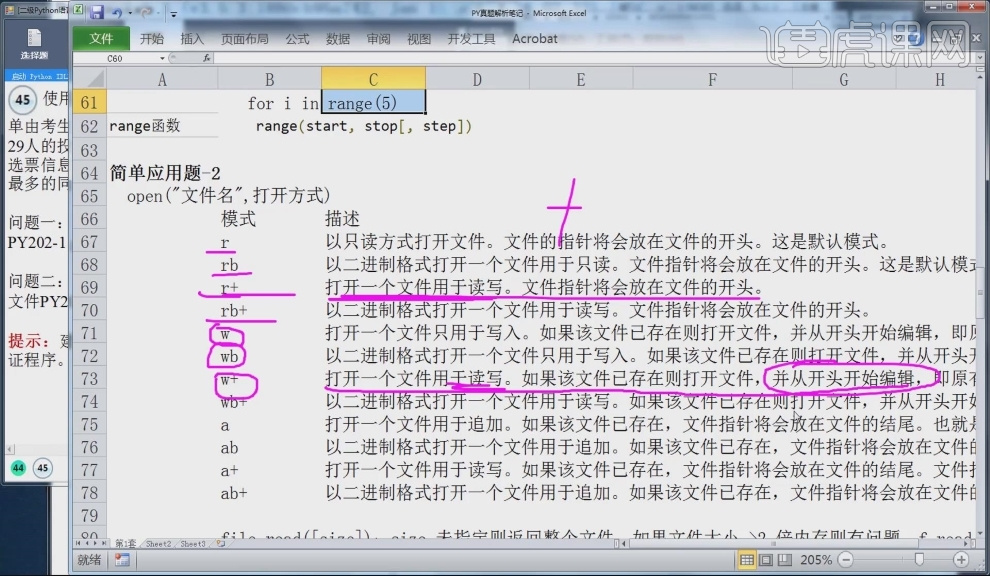
5.模式r+打开一个文件用于读写,模式rb+以二进制格式打开文件用于读写,模式w打开一个文件只用于写入,模式wb以二进制格式打开文件只用于写,模式w+打开一个文件用于读写,与模式r+不同的是w+会进行一个覆盖。
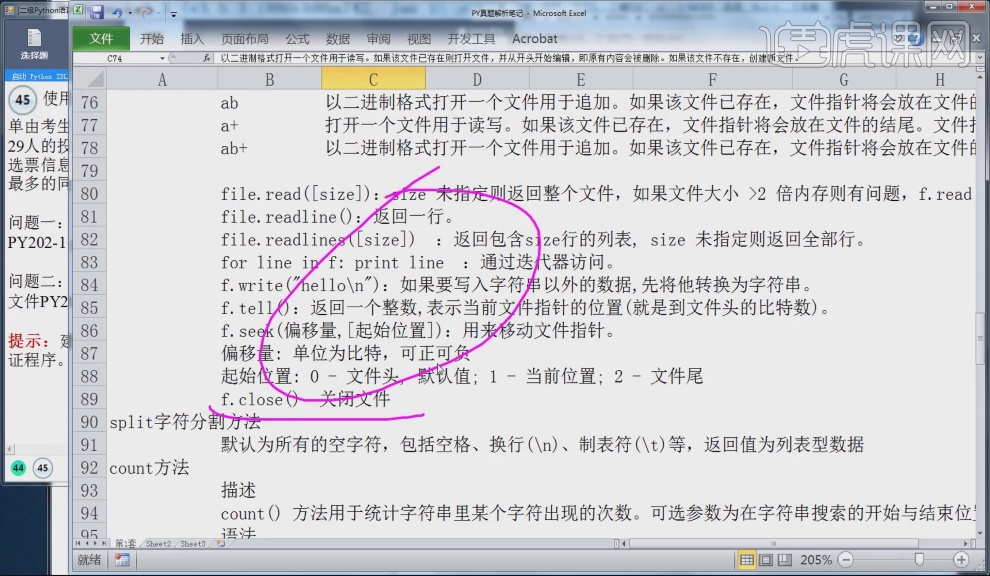
6.函数file.readline():读取文件里的一行,file.readlines([size]):读取文件里所有的内容,for line in f: print line:从f里面把所有行读取出来。
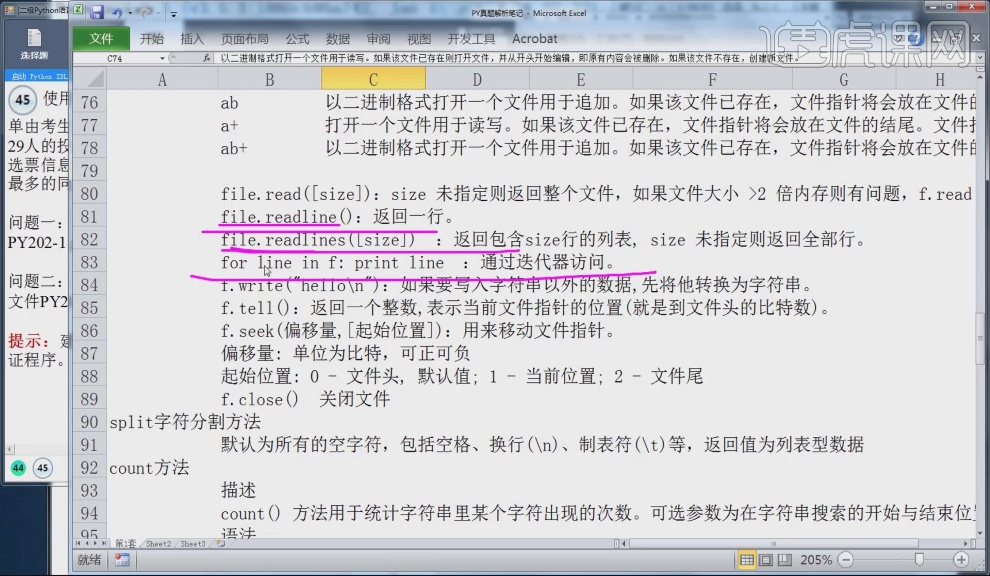
7.函数f.write("hello\n"):在文件里写入 hello后换行。
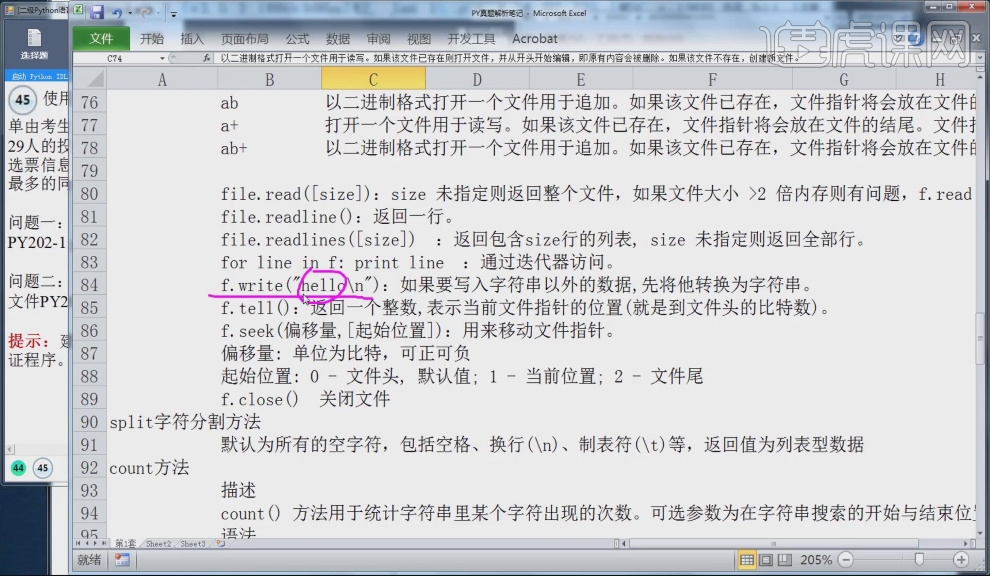
8.函数f.seek(偏移量,[起始位置]):用来移动文件指针,其中起始位置:0表示文件头,1表示当前位置,2表示文件尾,函数f.close() 关闭文件。
9.使用split字符分割后结果是一个列表型数据。

10.count()方法用于统计某字符出现的次数。
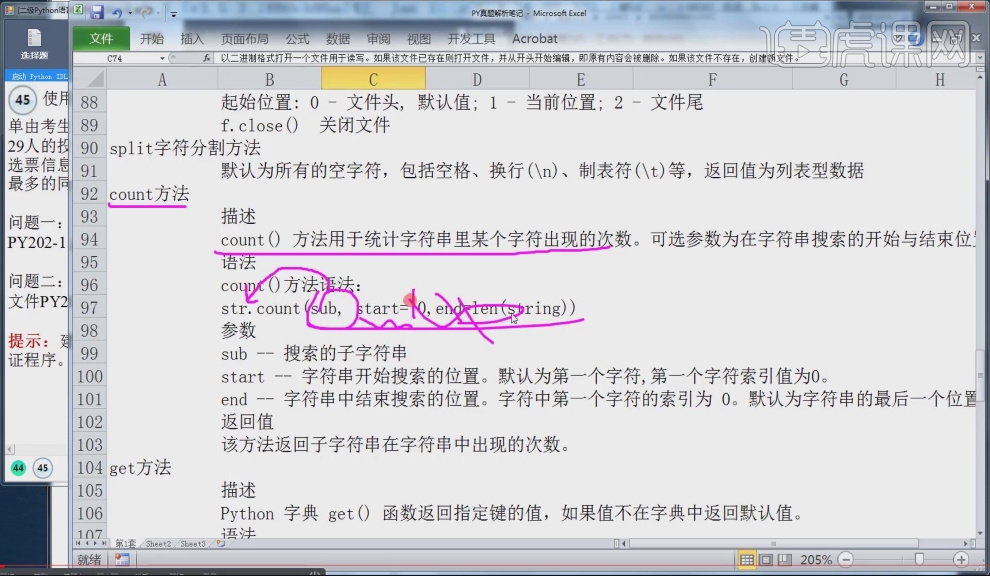
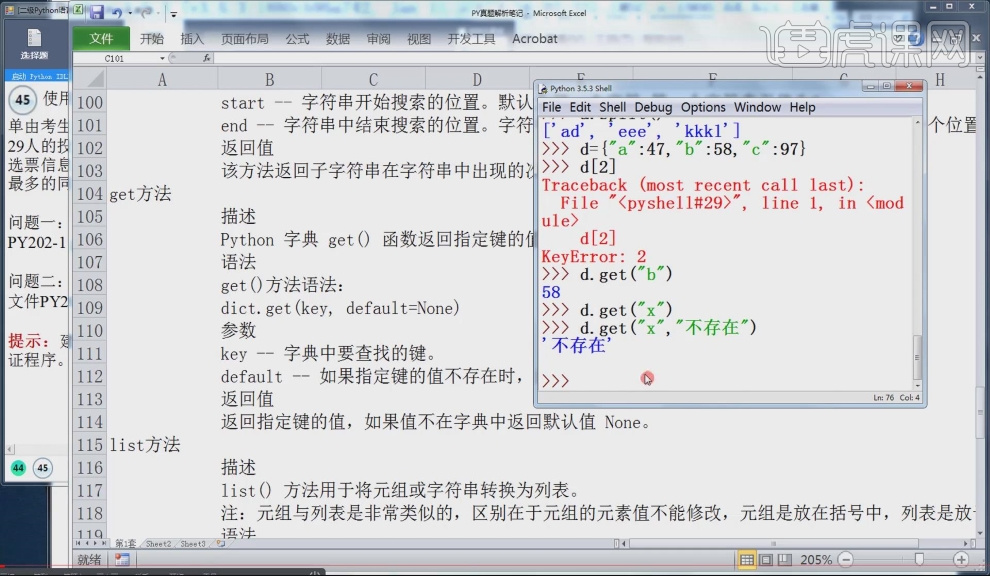
11.字典 get()函数,在字典型数据里面要获取某个键对应的值要使用get方法,当字典型数据里没有想要查询的键时可以使用默认值的方法。
12.list()方法用于将数据转变为列表型数据,在将a转换为列表后,a此时还是一个副本,需要使用a=list(a)将其转换为列表型数据,转换字典型时需要使用list(dict.item())。
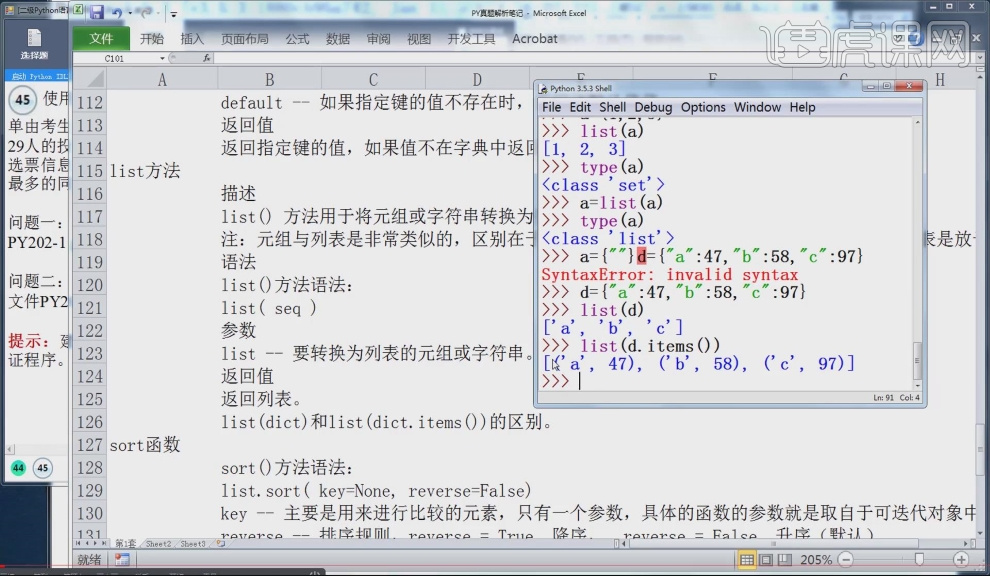
13.函数sort用于排序,列表型数据才可以进行排序,a.sort(reverse=False)为升序排序函数默认为降序排序,a.sort(reverse=True)为降序排序。
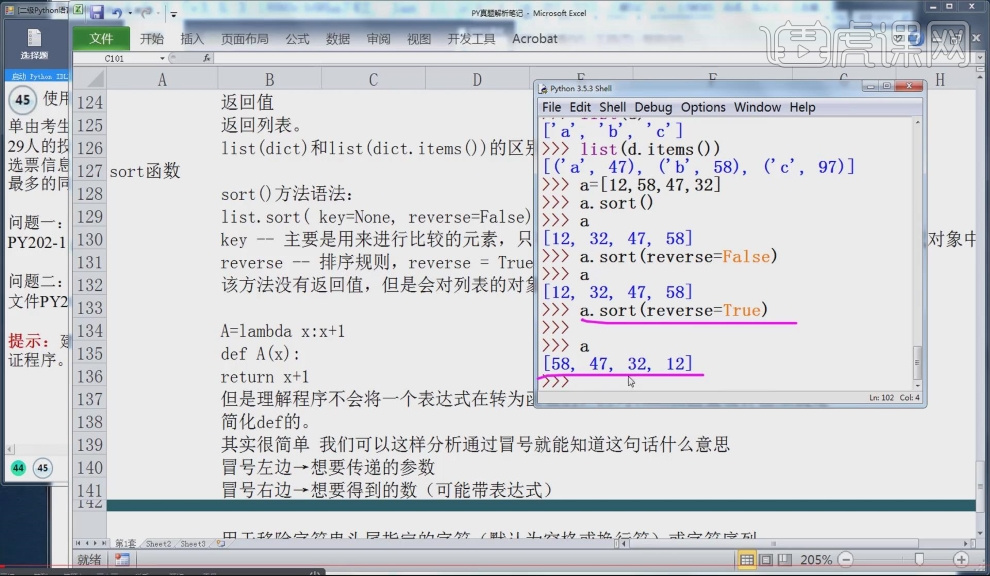
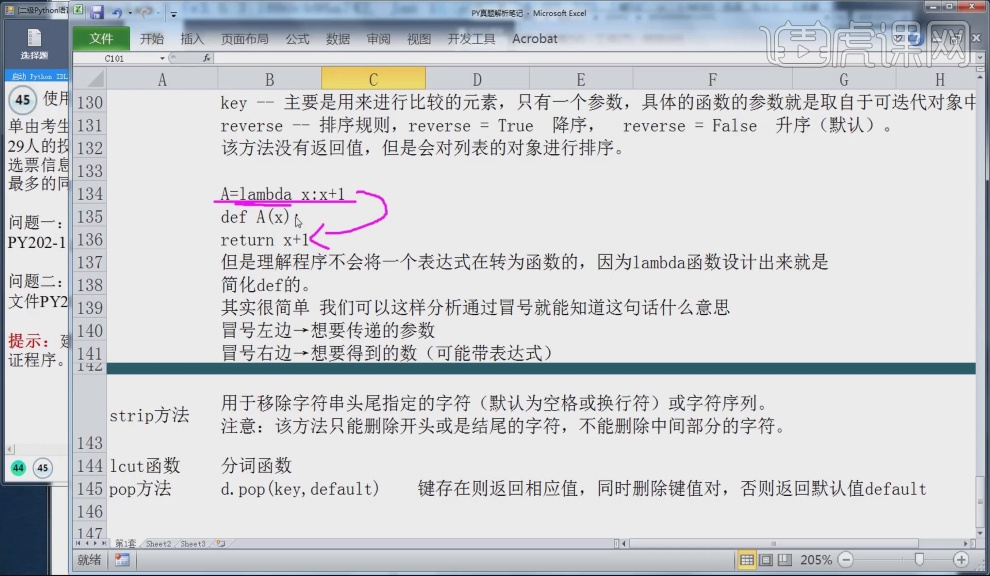
14.可以使用固定语句 A=lambda x;x+1 def A(x); return x+1,对字典型数据进行排序。
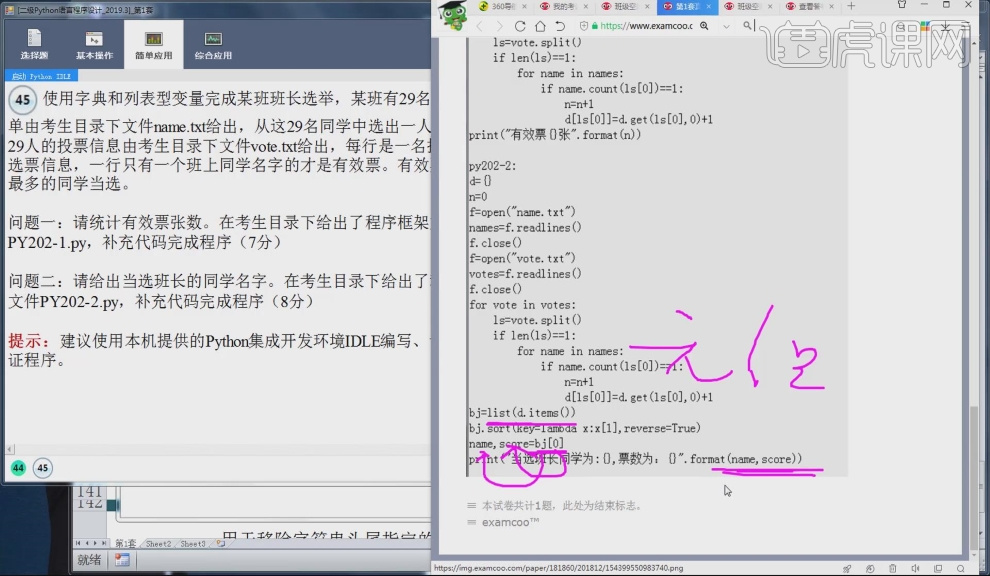
15.使用f=open("name.txt")打开文件,使用语句names=f.readlines()将文件里的所有的行全部读入到变量names中,使用同样方法打开vote.txt文件并读取到变量votes中。
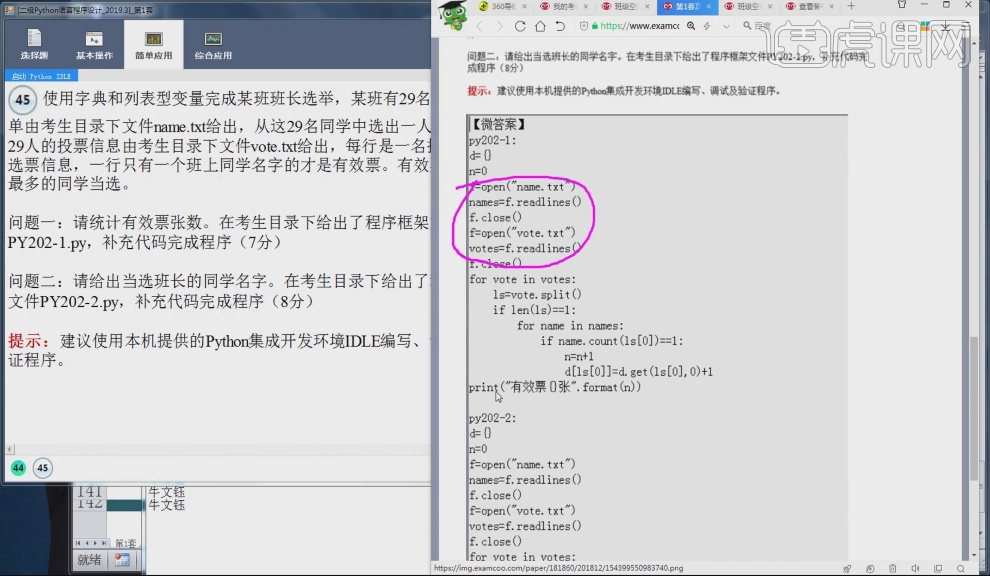
16.使用语句for vote in votes:将字符串votes每一行的数据都读出来,ls=vote.split()进行分割,分割后数据会变成列表型数据,if len(ls)=1:进行判断是否符合条件,当等于1时符合条件,当等于2时不符合条件,for name is names: if name.count(ls[0])==1: n=n+1 d[ls[0]]=d.get(ls[0],0)+1 统计每个人的有效票数,print("有效票数{},format(n)")输出。
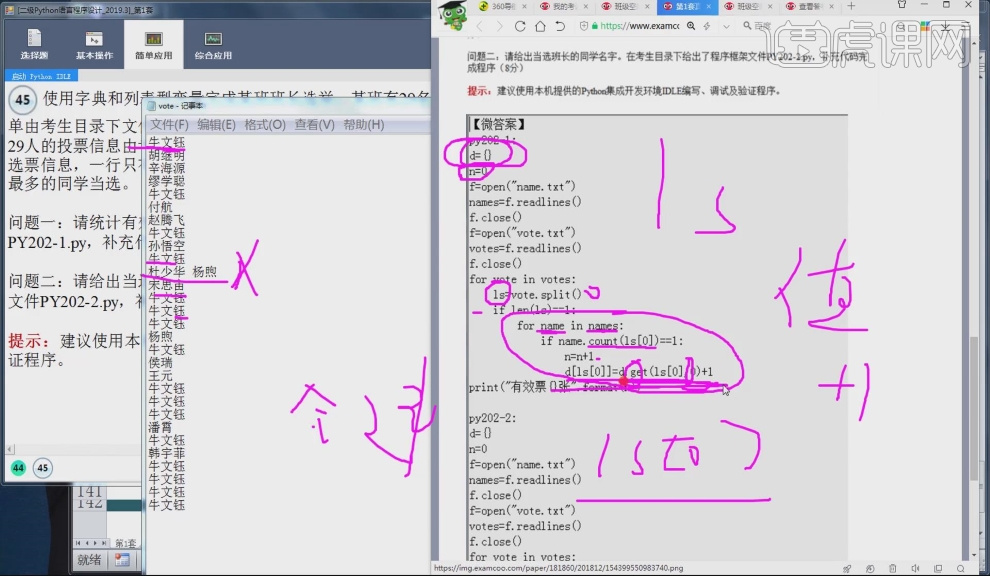
17.解题思路:(1), 把两个文件中内容,存储到字符串变量中。对应代码:f=open("name.txt") names=f.readlines() (2),判断投票文档中的投票是否有效。逐行对投票的结果进行读取读取后,进行划分变量就变成列表型数据,再利用len函数进行判断。对应代码:for vote in votes: ls=vote.split() if len(ls)=1: (3),通过判断名字出现的次数为1,计为有效票。对应代码:for name is names: if name.count(ls[0])==1: n=n+1 d[ls[0]]=d.get(ls[0],0)+1 。
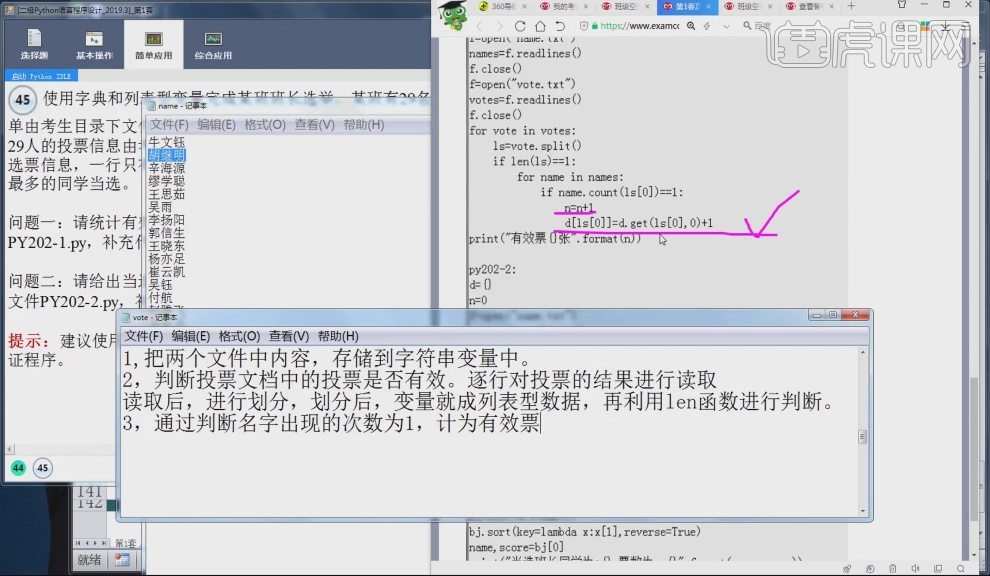
18.问题二:前半段的程序与问题一的程序相同,不同处使用语句bj=list(d.items()),把字典型数据转换为列表型数据,bj.sort(key=lambda x:x[1],reverse=True)降序排序,name,score=bj[0] 元祖bj[0]第一个数值传递给name第二个数值传递给score,print("当选班长的同学为:{},票数为:{}".format(name,score))输出。